Introduction
In the rapidly evolving landscape of artificial intelligence, the efficiency of underlying infrastructure often determines the pace of innovation. Meta, a company that serves billions of AI-powered experiences daily—from personalized recommendations to generative AI assistants—faces a unique challenge: optimizing its vast and heterogeneous hardware fleet. This article explores KernelEvolve, an autonomous kernel authoring system developed by Meta to streamline performance optimization across a diverse range of chips, including NVIDIA GPUs, AMD GPUs, custom MTIA silicon, and CPUs.
KernelEvolve is a key component of Meta's Ranking Engineer Agent, a system designed to accelerate innovation in ads ranking. While earlier posts covered the agent's machine learning exploration capabilities, this focus shifts to the low-level infrastructure that powers those models at scale. By treating kernel optimization as a search problem, KernelEvolve dramatically reduces the time and expertise required to fine-tune performance, yielding significant throughput improvements and broad applicability.
The Challenge of Heterogeneous Hardware
Meta operates a large and varied collection of hardware accelerators: NVIDIA GPUs, AMD GPUs, Meta's custom MTIA chips, and traditional CPUs. Effective utilization of this hardware demands software that translates high-level model operations into efficient, chip-specific instructions—known as optimized kernels. Unfortunately, authoring and optimizing these kernels is a labor-intensive process that must be repeated for each new chip generation and machine learning model architecture.
While standard operators like general matrix multiplications (GEMMs) and convolutions are covered by vendor libraries, production workloads often require many custom operators, especially in ranking models. With an increasing number of models multiplied by an expanding array of hardware types and generations, manual tuning by kernel experts simply does not scale. This bottleneck prompted Meta to develop KernelEvolve, which automates the search for optimal kernel implementations across multiple platforms.
How KernelEvolve Works
KernelEvolve reframes kernel optimization as a search problem. At its core is a purpose-built job harness that evaluates candidate kernels, feeds diagnostic information back to a large language model (LLM), and drives a continuous search over hundreds of alternatives. This approach contrasts with traditional manual optimization, where human experts rely on intuition and iterative profiling.
The system is designed to work with both high-level domain-specific languages (DSLs) like Triton, Cute DSL, and FlyDSL, as well as low-level languages such as CUDA, HIP, and MTIA C++. This versatility allows KernelEvolve to optimize across public and proprietary hardware without requiring separate toolchains. The agent explores a wide search space, automatically generating and testing kernel variants until it surpasses human-expert performance.
For a deeper technical dive, the paper “KernelEvolve: Scaling Agentic Kernel Coding for Heterogeneous AI Accelerators at Meta” will be presented at the 53rd International Symposium on Computer Architecture (ISCA) 2026.
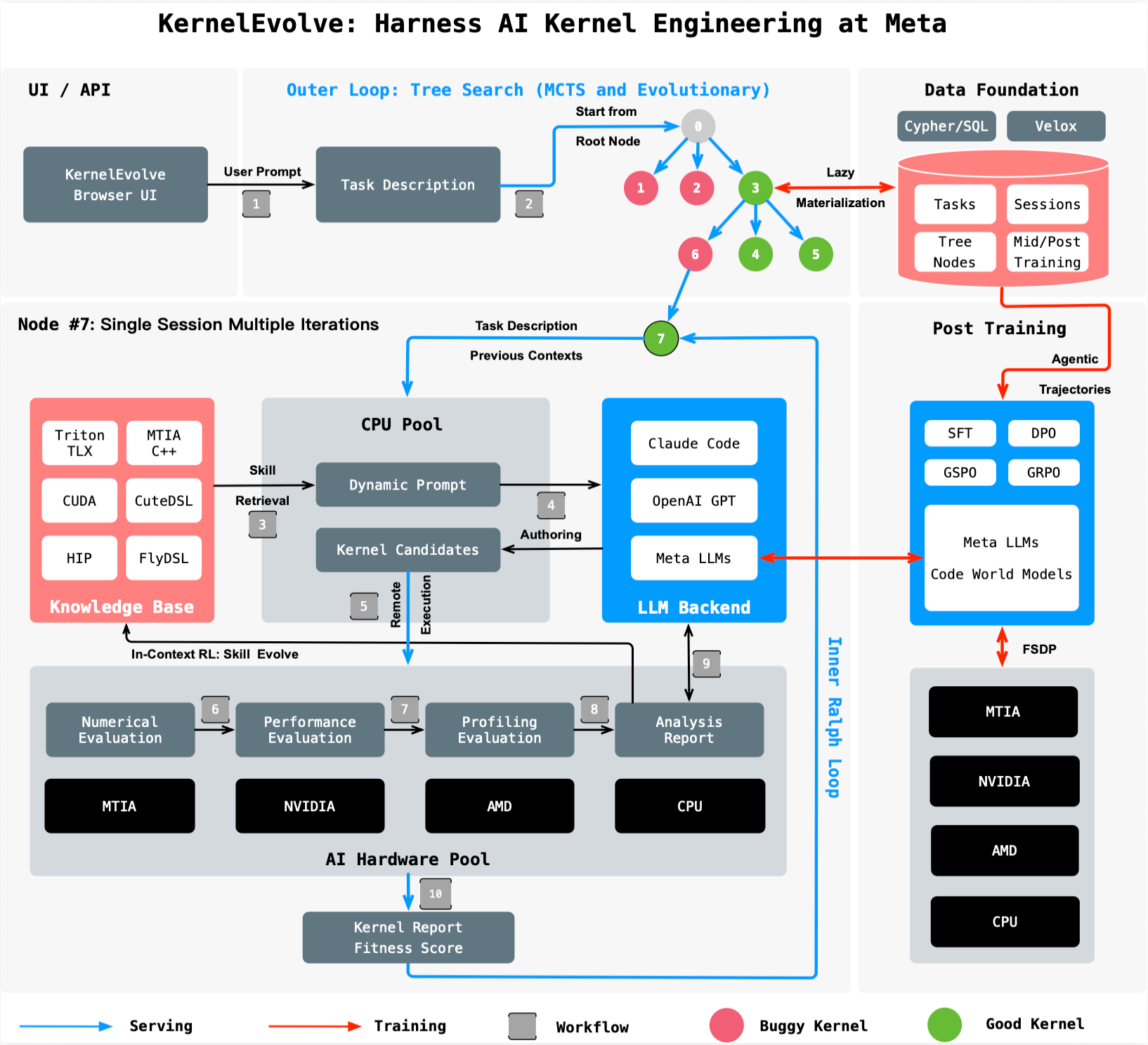
Performance Gains and Broad Applicability
KernelEvolve delivers three key benefits: faster development, better performance, and broad applicability.
- Faster development: The system compresses weeks of expert engineering time—typically spent profiling, optimizing, and debugging across hardware—into just hours of automated search and evaluation. This frees engineers to focus on higher-level innovations.
- Better performance: Real-world results are striking. For Meta's Andromeda Ads model on NVIDIA GPUs, KernelEvolve achieved over 60% inference throughput improvement. On Meta's custom MTIA silicon chips, a training throughput improvement of more than 25% was recorded for an ads model.
- Broad applicability: The agent works across NVIDIA GPUs, AMD GPUs, MTIA chips, and CPUs, generating kernels in multiple DSLs and low-level languages. This flexibility ensures that as new hardware emerges, optimization efforts can be rapidly scaled.
These improvements are critical for Meta's large-scale AI services, where even modest performance gains translate into significant cost savings and user experience enhancements. By automating the tedious and complex work of kernel authoring, KernelEvolve unlocks new levels of efficiency.
Conclusion
KernelEvolve represents a paradigm shift in how AI infrastructure is optimized. Instead of relying solely on human experts to hand-tune kernels for every hardware generation, Meta has created an autonomous agent that can search through thousands of possibilities to find the best implementation. This not only accelerates development cycles but also ensures that performance continues to improve as models and hardware evolve.
By integrating KernelEvolve into the Ranking Engineer Agent, Meta has demonstrated a practical path toward scaling AI innovation without proportional increases in engineering resources. The system's success on both public and proprietary hardware suggests broad applicability across the industry. As AI models grow more complex and hardware diversity increases, autonomous optimization tools like KernelEvolve will likely become essential components of any large-scale AI infrastructure.